Собственный LLM, "бесплатно и без СМС"
В этой статье мы поговорим про развертывание связки Ollama + Open Web UI на собственном сервере, а также поговорим об инструментах позволяющих использовать Ollama на практике и используемых моделях.


В этой статье мы поговорим про развертывание связки Ollama
+ Open Web UI на собственном сервере, а также поговорим об инструментах позволяющих использовать Ollama на практике и используемых моделях.
Установка Ollama довольно проста как на Linux, так и на Windows системах и не требует особых навыков. Что бы установить Ollama на свой Linux сервер, потребовалось всего-навсего запустить скрипт: curl -fsSL https://ollama.com/install.sh | sh
С точки зрения использования Ollama довольно сильно напоминает Docker. Мы так же как и образ Docker можем легко загрузить и запустить языковую модель. Загрузив и запустив модель мы можем пообщаться с ней прямо в терминале.
В целом если вы планируете использовать Ollama локально, этого вполне достаточно что бы запустить некоторые инструменты, о которых мы поговорим далее в статье. Моей целью же было, настроить Ollama сервер доступный из сети, что бы иметь возможность использовать его с любого устройства, а так же развернуть Open Web UI для привычного взаимодействия с языковыми моделями, как с ChatGPT.
Настройка сервера
Ollama помимо прочего, запускается как web-сервер с собственным REST API. Именно через этот API различные инструменты получают возможность взаимодействовать с Ollama. К сожалению по умолчанию Ollama не предоставляет инструментов защиты этого API, поэтому придется организовать их самостоятельно.
Для этого я использовал NGinx в качестве proxy сервера. Для моих целей мне потребовалось создать два сайта:
- Для внешнего использования, с проверкой API ключа в заголовке
- Для внутреннего использования контейнером с Open Web UI и доступом только с localhost
Настройка NGinx прокси для внешнего использования
Я создал файл конфигурации NGinx sudo micro /etc/nginx/sites-available/ollama (в моем случае я использую редактор micro) и создал базавую конфигурацию:
map $http_authorization $is_authorized {
default 0;
"Bearer API_KEY" 1; #
}
server {
listen 80;
server_name ollama.gxc-solutions.ru;
if ($host = ollama.gxc-solutions.ru) {
return 301 https://$host$request_uri;
}
return 404;
}
Конфигурация определяет список разрешённых заголовков для авторизации, в случае если заголовок не подходит возвращаться ошибка 401. С помщью certbot я получил SSL сертификат и настроил сайт для работы с ним. Теперь сервер Ollama минимально защищен от непрошенных гостей.
Настройка NGinx прокси для использования Open Web UI
К сожалению для Open Web UI невозможно настроить заголовки которые он будет отправляться в Ollama, поэтому для стандартного порта Ollama - 11434 я разрешил подключения только из подсети Docker. Таким образом для внешних подключений Ollama будет использоваться с NGinx прокси проверяющий заголовки авторизации, к оригинальному серверу же можно подключиться только с подсети Docker, что бы Open web UI смог с ним взаимодействовать.
Настройка Open Web UI
Open Web UI - это клиент поддерживающий работу с Ollama, иначе говоря это web-приложение позволяющее взаимодействовать с языковыми моделями наподобие известного ChatGPT.
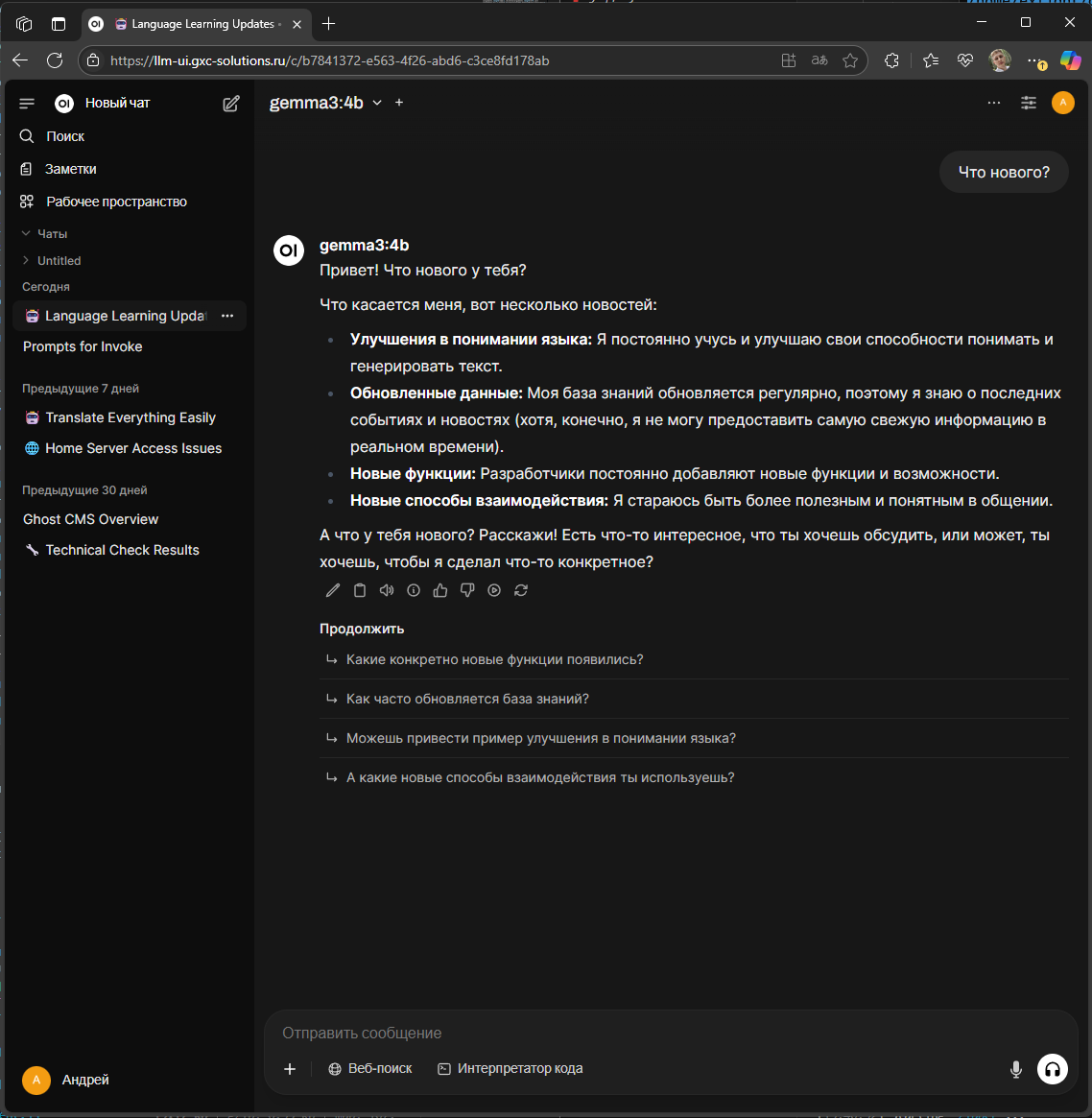
Здесь аналогично ChatGPT есть список чатов, возможности удалять, архивировать, клонировать и скачивать чаты, вести временный чат, а так же некоторые другие маленькие, но приятные полезности в интерфейсе.
Я разворачивал Open Web UI c помощью официального Docker контейнера. Для этого я подготовил файл docker-compose.yml со следующим содержимым:
services:
open-webui:
image: ghcr.io/open-webui/open-webui:cuda
container_name: open-webui
ports:
- "8080:8080"
runtime: nvidia
deploy:
resources:
reservations:
devices:
- capabilities: [gpu]
environment:
- OLLAMA_BASE_URL=http://172.19.0.1:11411
volumes:
- open-webui:/app/backend/data
extra_hosts:
- "host.docker.internal:172.19.0.1"
restart: always
volumes:
open-webui:
Для того что бы сайт открывался по доменному имени и через HTTPS я так же настроил прокси в NGinx и аналогично получил SSL сертификат LetsEncript с помощью certbot.
Continue - AI агент для IDE
Continue - это AI агент, расширение доступное для VSCode и JetBrains IDE, которое позволяет взаимодействовать с LLM прямо в редакторе. Такое решение как минимум позволяет избежать постоянного копирования фрагментов кода, сообщений об ошибках если при разработке активно используется языковая модель. Continue позволяет напрямую обращаться к файлам, терминалу, конкретным фрагментам кода и другим поставщикам данных.
Расширение добавляет в VSCode такие возможности как встроенный чат с LLM, режим агента (когда LLM может править или дополнять код в файлах) и режим автодополнения с подсказками от языковой модели.
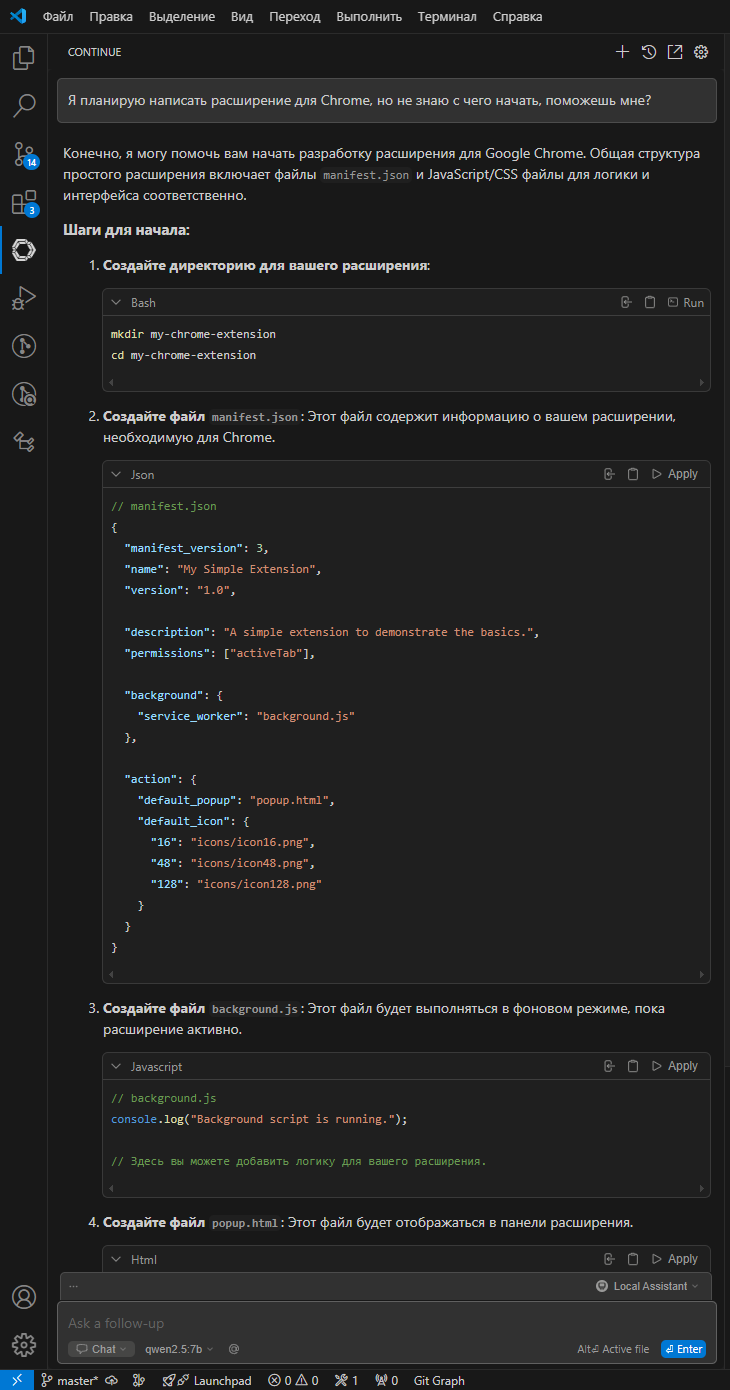

Примеры работы Coninue в VSCode
Конфигурация Continue настраивается через YML файл, в моем случае получилось нечто подобное:
name: Local Assistant
version: 1.0.0
schema: v1
models:
- name: Autodetect
provider: ollama
apiBase: "https://ollama.gxc-solutions.ru"
apiKey: "some_api_key_string"
model: AUTODETECT
- name: Qwen2.5-Coder 7.5B
provider: ollama
apiBase: "https://ollama.gxc-solutions.ru"
apiKey: "some_api_key_string"
model: qwen2.5-coder:7b
roles:
- autocomplete
context:
- provider: code
- provider: docs
- provider: diff
- provider: terminal
- provider: problems
- provider: folder
- provider: codebase
rules:
- Мой родной язык - русский язык, поэтому я хотел бы получать ответы на русском языке всегда.
- По возможности отвечай кратко и по делу, если у меня будут вопросы я задам их дополнительно.
В основном здесь доступы, определение доступных для модели контекстов. Из интересного rules - возможность добавить дополнительный контекст который будет подмешан к запросам.
Page assistent - расширение для браузера
Page assistent - браузерное расширение позволяющее взаимодействовать с LLM прямо в браузере. Из интересной функциональности - возможность извлекать данные со страницы и задавать вопросы о содержимом.
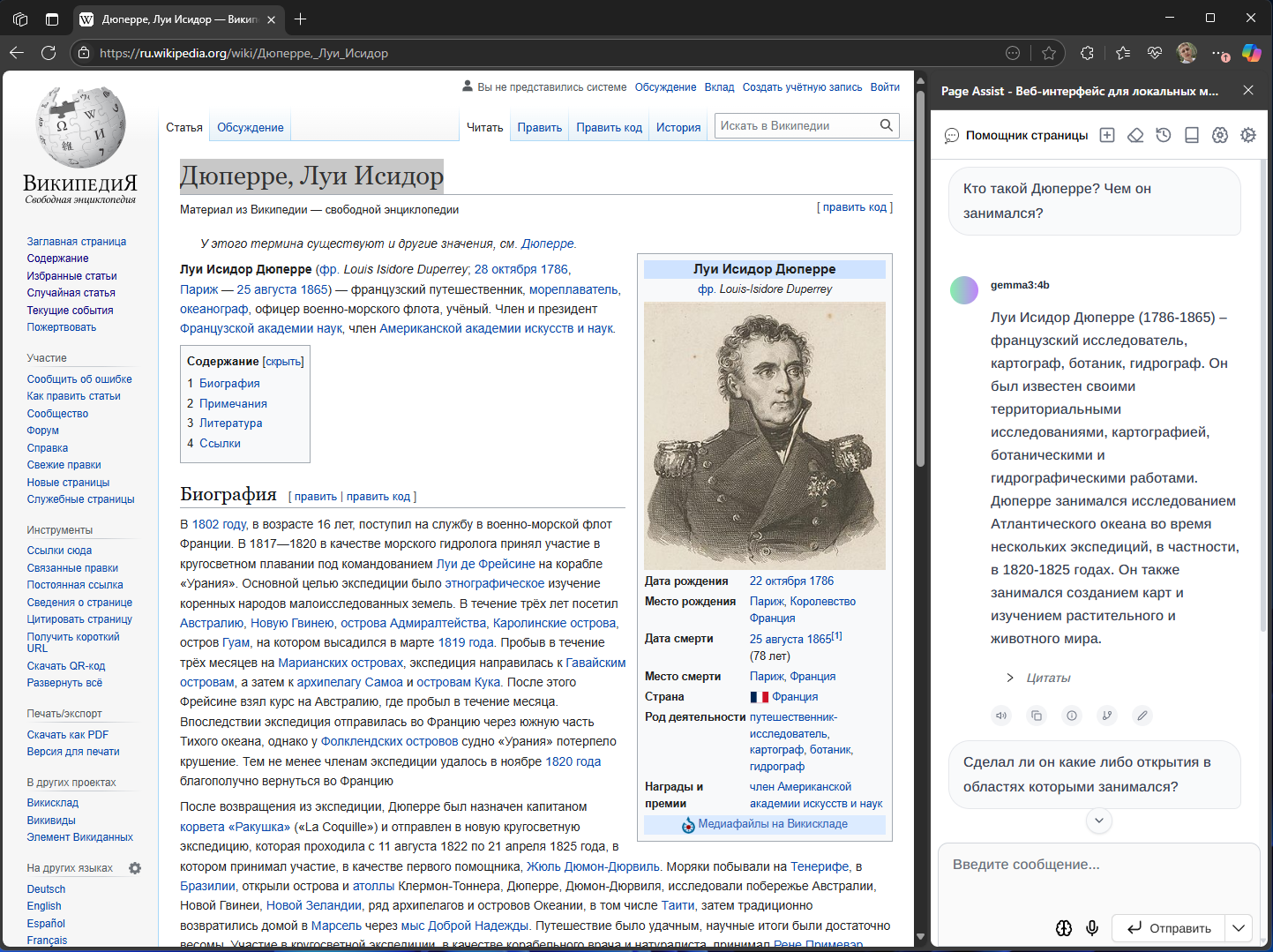
Реализовано подобное с помощью несложной RAG (Retrieval Augmented Generation) на основе так называемых embedding моделей, которую нам и предлагают выбрать в настройках расширения.
Идея здесь такова - embedding модель умеет преобразовывать текст в векторное представление. Исходный запрос конвертируется вектор, документ по которому происходит поиск, разбивается на части и так же преобразуется в вектор. Фрагмент с наиболее близким вектором подмешивается к исходному запросу и отдается на откуп LLM. Как итог LLM способна ответить на вопросы по текущему документу.
В связи с вышеописанным для более-менее серьезного использования рекомендую в настройках расширение выставить параметры Chunk Size и Chunk Overlap как минимум в пару раз больше, иначе спрашивать что-то чуть шире исходного вопроса теряет всякий смысл - модель просто будет отвечать отказами, ведь в этот момент у модели просто нет большего контекста чем предоставленный фрагмент.
Используемые модели
Из практического опыта довольно быстро стало понятно - модели физический размер которых превышает размер видеопамяти, генерируют контент довольно медленно. С учетом моего железа (его я описывал здесь) на данный момент я оставил модели физический размер которых не превышает 6gb. Это qwen-3:8b, qwen2.5-coder:7b, cogito:8b, gemma3:4b.
Модели которые поддерживают рассуждения за счет необходимости такового, генерируют контент также с ощутимыми задержками. Эти задержки вполне терпимы, но вот польза самих рассуждений у лично у меня пока остается под сомнением. По скромному опыту модель gemma3:4b, которая на данный момент является моим фаворитом, дает ответы не хуже модели рассуждений qwen-3:8b.
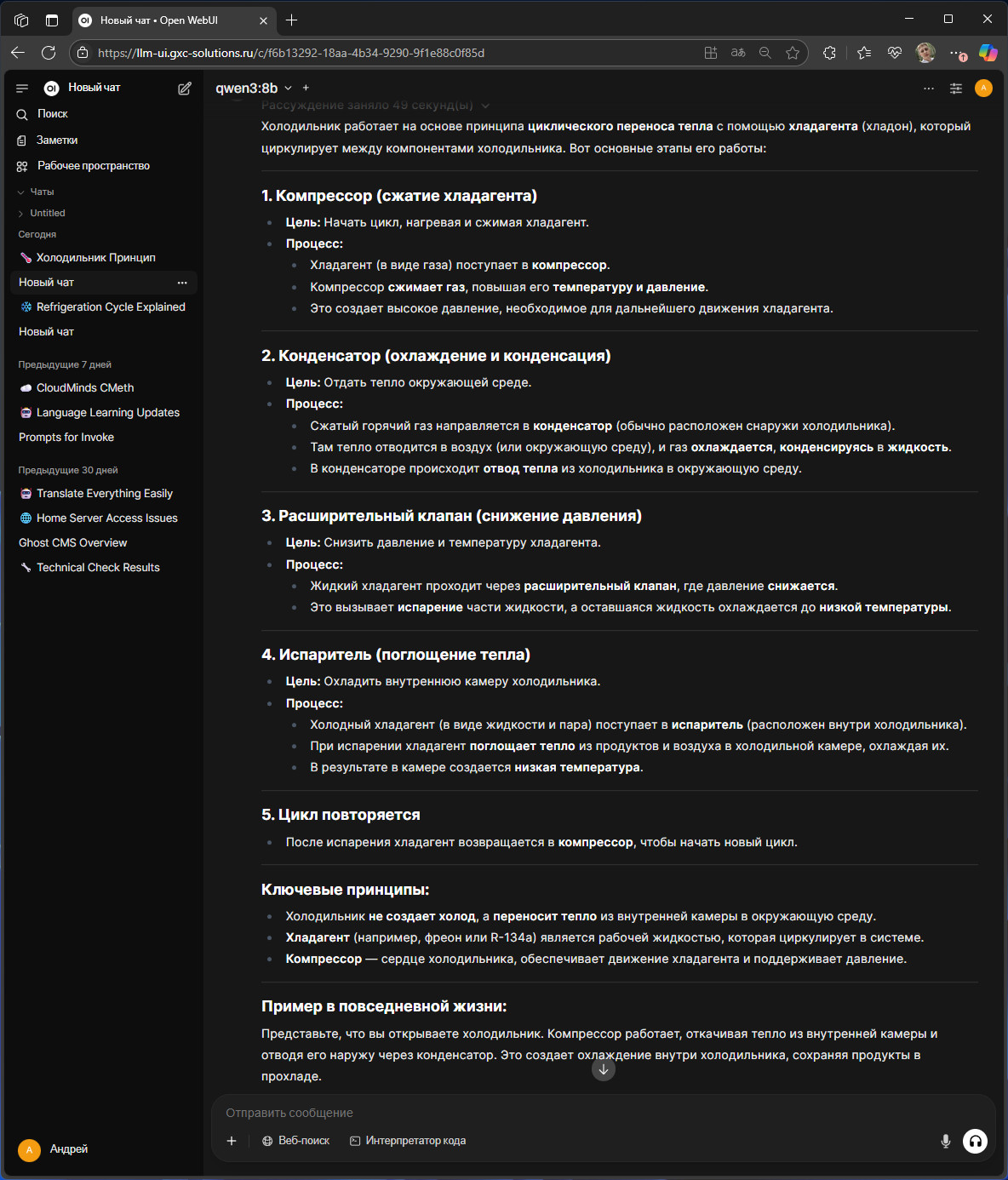
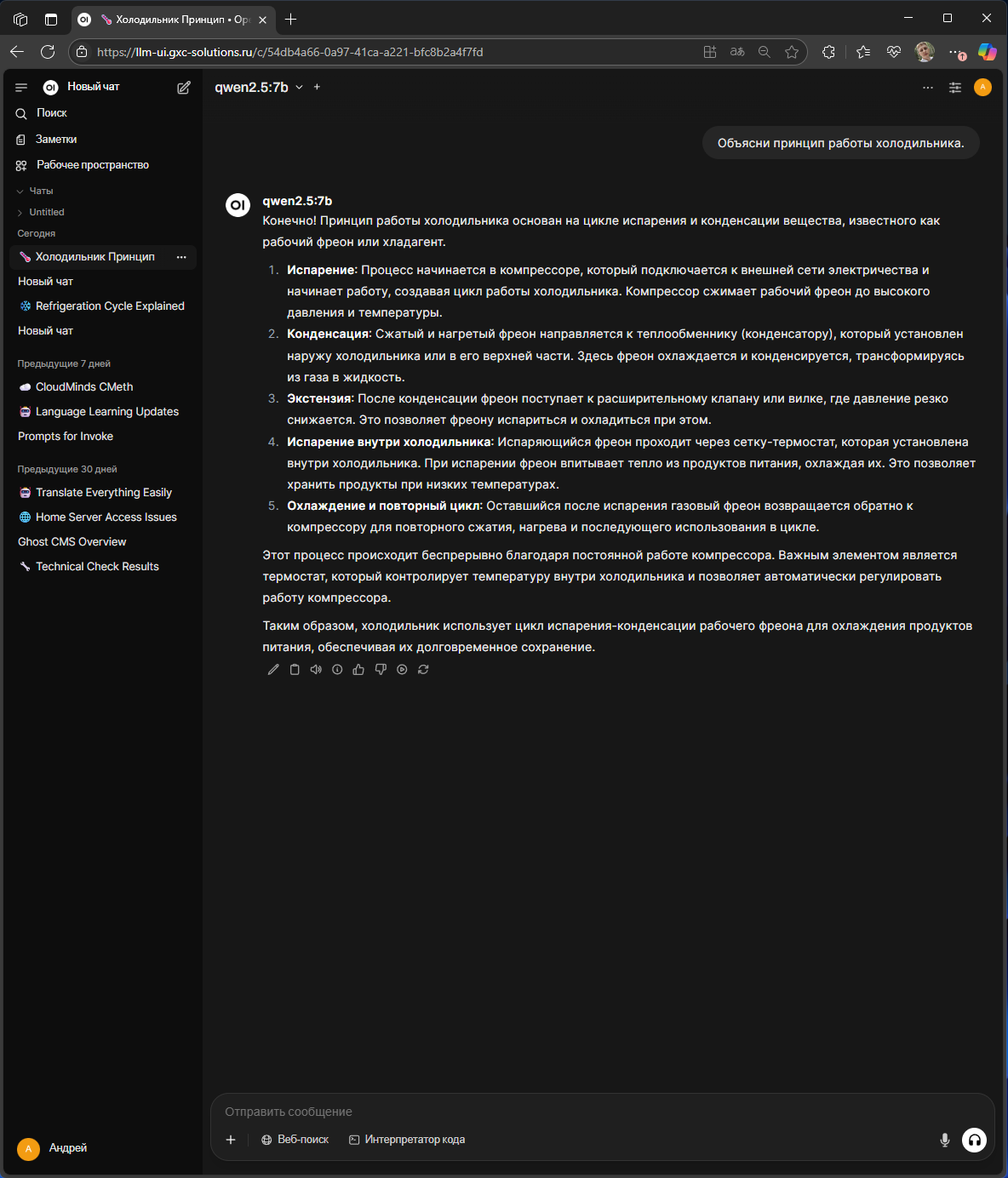
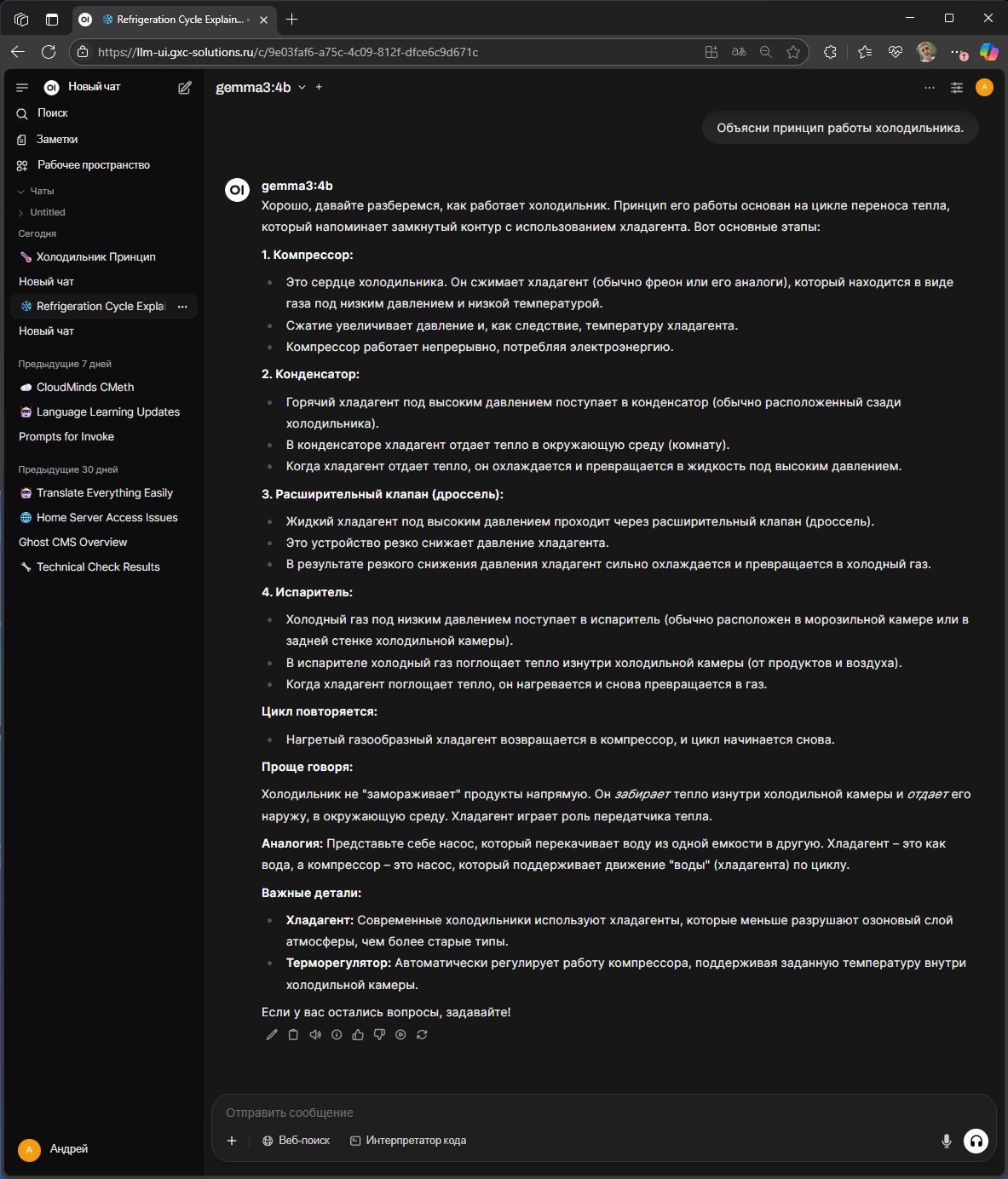
Сравнение ответов LLM моделей на просьбу объяснить принцип работы холодильника
На этом пожалуй завершаю статью, благодарю за ваше внимание и до встречи в следующих записях!